I've been working on a project where we allow users to provide us a .csv file and tell us about it, like what kind of data is in which column. Think of it like this: we have a fixed list of data points that we need to have mapped and the user is going to give us a file that contains all the data, but we don't know which column will have which piece of information so the user has to tell us. If we need First Name, Last Name, and Age, the user just has to tell us which column in their file has which value. We want to make that as easy as possible so we check the header in their file to see if we can deduce that information so the user doesn't have to. It's easy if the columns are named First Name, Last Name, and Age, but it gets a little trickier when they're named FName, LName, and AgeInYears. That's where fuzzy matching comes in.
We decided to use a library called Fuzzy Sharp (there are several with that name so be cautious when choosing one) to do the heavy lifting for us. It's pretty simple to use, but there are lots of options and the "documentation" isn't super clear. Fortunately in 2025 we have AI to help us make sense of the nonsensical!
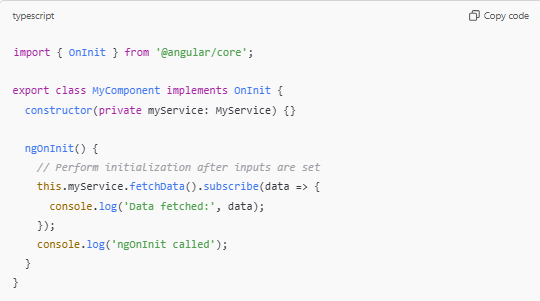
In our first attempt we checked for an exact match manually, then stripped off special characters from both sets for comparison and checked for another "exact" match, then finally relented and used the FuzzySharp library to check for a match:
private int FindSourceColumnNumber(string destinationName, IEnumerable<string> columnNames)
{
var exactMatch = columnNames.Select((name, index) => new { Name = name, Position = index })
.FirstOrDefault(a => a.Name.Equals(destinationName, StringComparison.OrdinalIgnoreCase));
if (exactMatch is not null)
{
return exactMatch.Position;
}
var strippedColumnNames = columnNames
.Select((name, index) => new {
Name = name,
Position = index,
StrippedName = SpecialCharacterReplacementRegex().Replace(name, "")
});
var strippedDestinationName = SpecialCharacterReplacementRegex().Replace(destinationName, "");
var strippedMatch = strippedColumnNames
.FirstOrDefault(name => string.Equals(name, strippedDestinationName, StringComparison.InvariantCultureIgnoreCase));
if (strippedMatch is not null)
{
return strippedMatch.Position;
}
var fuzzyMatch = strippedColumnNames
.Select((name, index) => new { Name = name, Position = index, Score = Fuzz.Ratio(strippedDestinationName, name) })
.Where(x => x.Score >= 70)
.OrderByDescendinx(x => x.Score)
.FirstOrDefault();
return fuzzyMatch is not null ? fuzzyMatch.Position : -1;
}
That was fine, but it turned out there was a much better way to do this by taking advantage of the FuzzySharp library. We were able to simplify our code to just this:
private int? FindSourceColumnNumber(string destinationName, IEnumerable<string> columnNames)
{
var exactMatch = columnNames.Select((name, index) => new { Name = name, Position = index })
.FirstOrDefault(a => a.Name.Equals(destinationName, StringComparison.OrdinalIgnoreCase));
if (exactMatch is not null)
{
return exactMatch.Position;
}
// Step 2: Fuzzy match (slower, but more flexible)
var fuzzyMatch = columnNames
.Select((name, index) => new { Name = name, Position = index, Score = Fuzz.Ratio(destinationName, name, PreprocessMode.Full) })
.Where(x => x.Score >= 70)
.OrderByDescending(x => x.Score)
.FirstOrDefault();
return fuzzyMatch is not null ? fuzzyMatch.Position : null;
}
Adding the
PreprocessMode.Full parameter tells FuzzySharp to strip out non-alphanumeric characters on its own. Since the authors of that library focused on speed and efficiency we've basically decided to trust that they're doing a better job with it than we were when we were using the Regex match capability. There's a ton more that FuzzySharp can do, but this is the extent of what we needed so I didn't delve too deep into its other features.